


NsfwJS+Python搭建违规图片检测API
AI-摘要
Tianli GPT
AI初始化中...
介绍自己
生成本文简介
推荐相关文章
前往主页
前往tianli博客
事情是这样的,因为smms的图床有容量限制,不太爽,所以自己在服务器上搭建了一个图床,准备免费公开使用,但是既然是公开,就不免有人上传一些不正常的东西到图床上,所以为了防止诈骗等违规图片搭建了一个基于NsfwJS+Tesseract-ocr+Pyzbra的接口,检测图片内是否含有违规内容
代码
直接粘贴代码会有格式问题,故上传文件
到手之后可以根据注释更改如下变量,wjcjc:严重级违禁词,wjc:一般违禁词,nsfwjs_level:Nsfwjs敏感度
环境部署
环境:Centos 7.9
NsfwJS
一般可以使用docker部署NsfwJS,这是最简单的
以下参考这位大神:NSFW-API 开源的图片鉴黄API - ROYWANG
在宝塔环境中安装Docker管理器,导入镜像
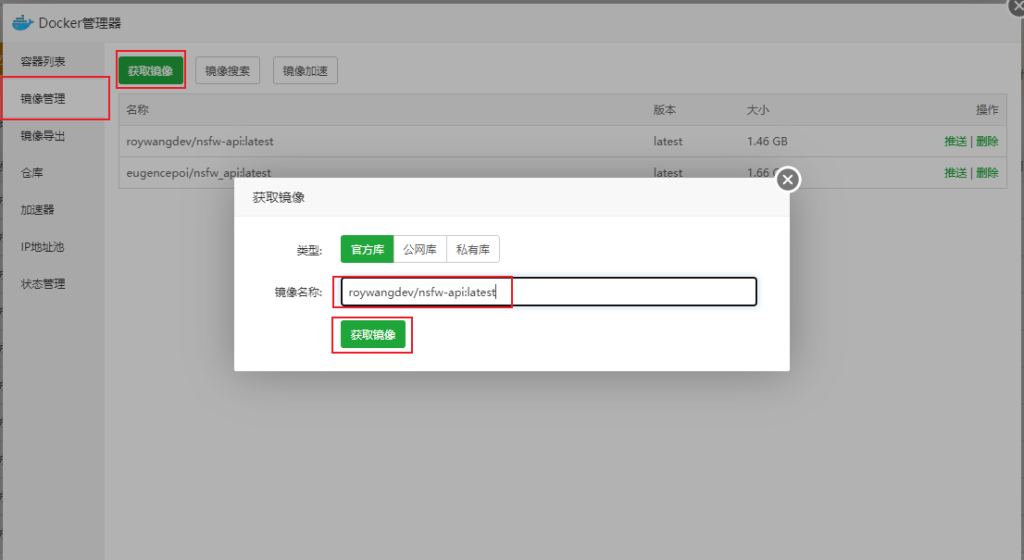
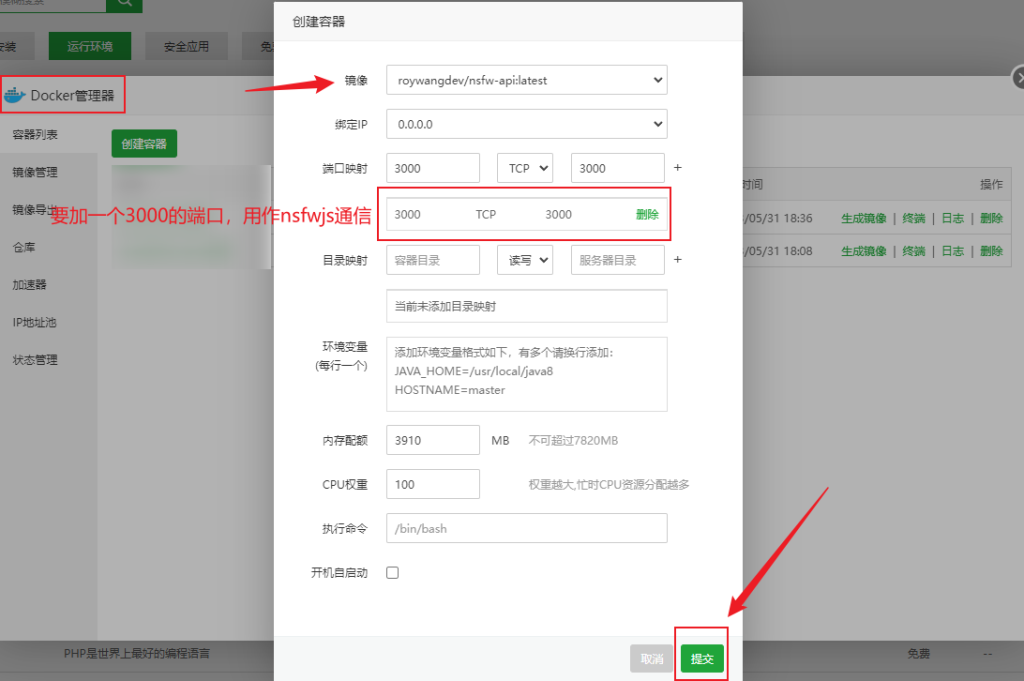

看到在运行中就行了
Tesseract-ocr
Centos安装Tesseract-OCR比较复杂,有很多坑
参考:centos下tesseract-ocr的安装 - 稀土掘金
这里过程就不详细讲了,可以去看上面的文章,列举一下踩的坑
1.C++会话版本错误
Your compiler does not have the necessary C++17 support!这个错误一般是在编译过程出现的,解决方法:
在SSH依次运行
yum install -y centos-release-scl
yum install devtoolset-8-gcc*
scl enable devtoolset-8 bash然后再编译就可以了
2.Leptonica环境变量错误
这个错误也是在编译过程中出现的
解决方法:
在SSH中vim /etc/profile,然后在最后添加如下设置
export LD_LIBRARY_PATH=$LD_LIBRARY_PAYT:/usr/local/lib
export LIBLEPT_HEADERSDIR=/usr/local/include
export PKG_CONFIG_PATH=/usr/local/lib/pkgconfig保存退出,输入如下指令,使环境变量生效
source /etc/profile3.环境变量or字体错误
pytesseract.pytesseract.TesseractError: (1, u'Tesseract Open Source OCR Engine v3.04.00 with Leptonica Error opening data file /usr/local/share/tessdata/eng.traineddata Please make sure the TESSDATA_PREFIX environment variable is set to the parent directory of your "tessdata" directory. Failed loading language \'eng\' Tesseract couldn\'t load any languages! Could not initialize tesseract.')这个错误是在代码运行时出现的,一般原因有两种,一种是环境变量错误,另一种是字体文件有问题,解决方法也很简单,重新去github下载字体文件,然后再在SSH里vim打开/etc/profile文件,在最后添加如下设置
export TESSDATA_PREFIX=/usr/local/share/tessdata保存退出,输入如下指令,使环境变量生效
source /etc/profile这两个环境装好就可以运行了
- 感谢你赐予我前进的力量
-
 微信
微信  支付宝
支付宝
赞赏者名单
因为你们的支持让我意识到写文章的价值🙏
本文是原创文章,采用 CC BY-NC-SA 协议,完整转载请注明来自 Lowion.cn


评论
匿名评论
隐私政策
你无需删除空行,直接评论以获取最佳展示效果




